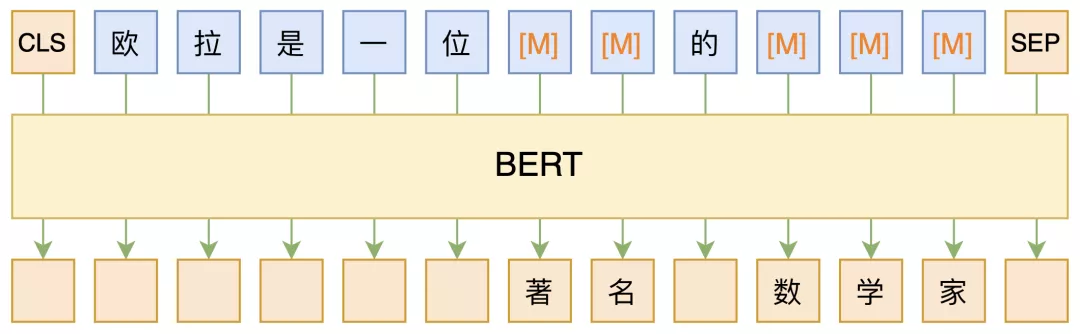
MLM MLM,全称 “Masked Language Model”,可以翻译为 “掩码语言模型”,实际上就是一个完形填空任务,随机 Mask 掉文本中的某些字词,然后要模型去预测被 Mask 的字词,示意图如下:
其中被 Mask 掉的部分,可以是直接随机选择的 Token,也可以是随机选择连续的能组成一整个词的 Token,后者称为 WWM(Whole Word Masking)。
开始,MLM 仅被视为 BERT 的一个预训练任务,训练完了就可以扔掉的那种,因此有一些开源的模型干脆没保留 MLM 部分的权重,然而,随着研究的深入,研究人员发现不止 BERT 的 Encoder 很有用,预训练用的 MLM 本身也很有用。
将任务转成完形填空 在本文里,我们再学习 MLM 的一个精彩应用:用于小样本学习或半监督学习,某些场景下甚至能做到零样本学习。
怎么将我们要做的任务跟 MLM 结合起来呢?很简单,给任务一个文本描述,然后转换为完形填空问题 即可。举个例子,假如给定句子“这趟北京之旅我感觉很不错。”,那么我们补充个描述,构建如下的完形填空:
______满意。这趟北京之旅我感觉很不错。
进一步地,我们限制空位处只能填一个“很”或“不”,问题就很清晰了,就是要我们根据上下文一致性判断是否满意,如果“很”的概率大于“不”的概率,说明是正面情感倾向,否则就是负面的,这样我们就将情感分类问题转换为一个完形填空问题了,它可以用 MLM 模型给出预测结果,而 MLM 模型的训练可以不需要监督数据,因此理论上这能够实现零样本学习了。
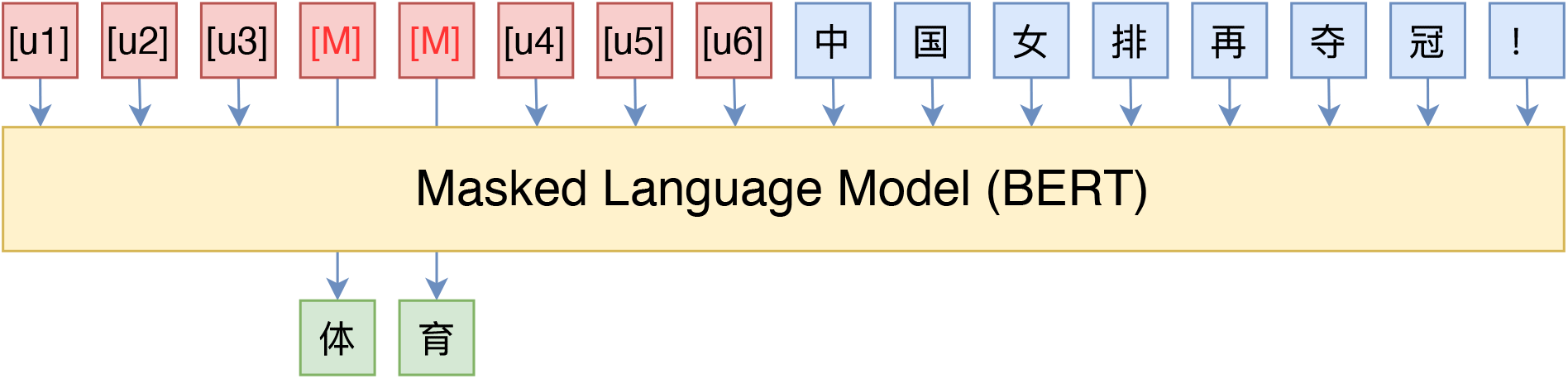
多分类问题也可以做类似转换,比如新闻主题分类,输入句子为“八个月了,终于又能在赛场上看到女排姑娘们了。”,那么就可以构建:
下面播报一则______新闻。八个月了,终于又能在赛场上看到女排姑娘们了。
这样我们就将新闻主题分类也转换为完形填空问题了,一个好的 MLM 模型应当能预测出“体育”二字来。
还有一些简单的推理任务也可以做这样的转换,常见的是给定两个句子,判断这两个句子是否相容,比如“我去了北京”跟“我去了上海”就是矛盾的,“我去了北京”跟“我在天安门广场”是相容的,常见的做法就是将两个句子拼接起来输入到模型做,作为一个二分类任务。如果要转换为完形填空,那该怎么构造呢?一种比较自然的构建方式是:
我去了北京?______,我去了上海。
我去了北京?______,我在天安门广场。
其中空位之处的候选词为 {是的, 不是} 。
PET (Pattern-Exploiting Training) 给输入的文本增加一个前缀或者后缀描述,并且 Mask 掉某些 Token,转换为完形填空问题,这样的转换在原论文中称为 Pattern ,这个转换要尽可能与原来的句子组成一句自然的话,不能过于生硬,因为预训练的 MLM 模型就是在自然语言上进行的。
然后,我们需要构建预测 Token 的候选空间,并且建立 Token 到实际类别的映射,这在原论文中称为 Verbalizer ,比如情感分类的例子,我们的候选空间是{ 很, 不} ,映射关系是 很->正面 ,不->负面 ,候选空间与实际类别之间不一定是一一映射,比如我们还可以加入“挺”、“太”、“难”字,并且认为 {很,挺,太}->正面 以及 {不,难}->负面 ,等等。
不难理解,不少 NLP 任务都有可能进行这种转换,但显然这种转换一般只适用于候选空间有限 的任务,说白了就是只用来做选择题 ,常见任务的就是文本分类 。
刚才说了,同一个任务可以有多种不同的 Pattern,原论文是这样处理的:
样本数量比较少,没有大量的标注数据怎么办?先用标注数据 training data,进行 pattern 数据生成,然后将 pattern 部分进行 mask, finetune 一个 MLM 模型;
因为有多种 pattern, 这样我们就有了多个基于 training data 的 MLM 模型,因为不知道哪种 pattern 是最好的,所以将多个模型进行集成,得到一个融合模型;
用这个融合模型,对 unlabeled data 进行预测,每个 data 都得到了一个伪标签 (soft label);
用拥有伪标签的这部分 unlabeled data 去 finetune 一个分类模型,用于最终的分类预测。
注:如果使用了 Auxilliary Language Modeling,那么在第一步的时候,除了用 training data,mask 掉 pattern 的部分作为训练数据,还要使用 unlabeled data,随机 mask 掉一部分 token,然后对其预测。目的是为了能让 model 更好的适应当前的 domain。
P-tuning 自动构建模版,释放语言模型潜能 讲解:P-tuning:自动构建模版,释放语言模型潜能 - 科学空间|Scientific Spaces (kexue.fm)
Code:P-tuning: A novel method to tune language models. Codes and datasets for paper ``GPT understands, too’’.
直观来看,模版就是由自然语言构成的前缀/后缀,通过这些模版我们使得下游任务跟预训练任务一致,这样才能更加充分地利用原始预训练模型,起到更好的零样本、小样本学习效果。
等等,我们真的在乎模版是不是“自然语言”构成的吗?
并不是。本质上来说,我们并不关心模版长什么样,我们只需要知道模版由哪些 token 组成,该插入到哪里,插入后能不能完成我们的下游任务,输出的候选空间是什么。 模版是不是自然语言组成的,对我们根本没影响,“自然语言”的要求,只是为了更好地实现“一致性”,但不是必须的。于是,P-tuning考虑了如下形式的模版:
这里的[u1]~[u6],代表BERT词表里边的[unused1]~[unused6],也就是用几个从未见过的 token 来构成模板,这里的 token 数目是一个超参数,放在前面还是后面也可以调整。接着,为了让“模版”发挥作用,我们用标注数据来求出这个模板。
BigBird p-tuning code
Reference code: https://github.com/bojone/P-tuning/blob/main/bert.py
1 2 3 4 5 6 7 8 9 10 11 12 import pandas as pddef load_data (filename ): D = [] data = pd.read_csv(filename) for i in range (len (data)): D.append((data['titletext' ][i], int (data['label' ][i]))) return D test_data = load_data('./new_data/test_data.csv' ) train_data = load_data('./new_data/train_data.csv' ) valid_data = load_data('./new_data/valid_data.csv' )
1 2 3 4 5 6 7 from transformers import BigBirdTokenizer, BigBirdForMaskedLMtokenizer = BigBirdTokenizer.from_pretrained('google/bigbird-roberta-base' ) PAD_INDEX = tokenizer.convert_tokens_to_ids(tokenizer.pad_token) UNK_INDEX = tokenizer.convert_tokens_to_ids(tokenizer.unk_token) MASK_INDEX = tokenizer.convert_tokens_to_ids(tokenizer.mask_token)
1 2 3 4 5 """ 因为 BigBird 的 tokenizer 里面没有 "opinion" 和 "unused1"... 的 token,所以我们要先自己新加上这几个 token. """ tokenizer.add_tokens('opinion' ) desc = ['[unused%s]' % i for i in range (1 , 9 )] for item in desc: tokenizer.add_tokens(item)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import numpy as npdef random_masking (token_ids ): """ 对输入进行随机 mask """ rands = np.random.random(len (token_ids)) source, target = [], [] for r, t in zip (rands, token_ids): if r < 0.15 * 0.8 : source.append(MASK_INDEX) target.append(t) elif r < 0.15 * 0.9 : source.append(t) target.append(t) elif r < 0.15 : source.append(np.random.choice(tokenizer.vocab_size - 1 ) + 1 ) target.append(t) else : source.append(t) target.append(0 ) return source, target
1 2 3 4 5 6 7 8 """ 对应的任务描述 """ mask_idx = 5 desc = ['[unused%s]' % i for i in range (1 , 9 )] desc.insert(mask_idx - 1 , tokenizer.mask_token) desc_ids = [tokenizer.convert_tokens_to_ids(t) for t in desc] pos_id = tokenizer.convert_tokens_to_ids('opinion' ) neg_id = tokenizer.convert_tokens_to_ids('report' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 from torch.utils.data import Datasetclass MaskDataset (Dataset ): def __init__ (self, tokenizer, data, max_len, random=True ): self.token_ids_list, self.output_ids_list = [], [] for item in data: data_text = item[0 ] data_label = item[1 ] token_ids = tokenizer.encode(data_text) token_ids = token_ids[:max_len] if data_label != 2 : token_ids = token_ids[:1 ] + desc_ids + token_ids[1 :] if random: source_ids, target_ids = random_masking(token_ids) else : source_ids, target_ids = token_ids[:], token_ids[:] if data_label == 0 : source_ids[mask_idx] = MASK_INDEX target_ids[mask_idx] = neg_id elif data_label == 1 : source_ids[mask_idx] = MASK_INDEX target_ids[mask_idx] = pos_id source_ids.extend((max_len+9 -len (source_ids))*[PAD_INDEX]) target_ids.extend((max_len+9 -len (target_ids))*[PAD_INDEX]) self.token_ids_list.append(source_ids) self.output_ids_list.append(target_ids) if len (self.token_ids_list) != len (self.output_ids_list): raise Exception("The length of X does not match the length of Y" ) def __len__ (self ): return len (self.token_ids_list) def __getitem__ (self, index ): _x = self.token_ids_list[index] _y = self.output_ids_list[index] return _x, _y
1 2 3 4 5 6 7 """ 没有这个函数,DataLoader 返回的是一个 list, 用这个将结果转为 tensor """ def collate_fn (data ): unit_x, unit_y = [], [] for item in data: unit_x.append(item[0 ]) unit_y.append(item[1 ]) return {torch.tensor(unit_x), torch.tensor(unit_y)}
1 2 3 4 5 6 7 8 9 10 11 12 from torch.utils.data import DataLoaderMAX_SEQ_LEN = 896 BATCH_SIZE = 2 train_set = MaskDataset(tokenizer, train_data, MAX_SEQ_LEN) valid_set = MaskDataset(tokenizer, valid_data, MAX_SEQ_LEN) test_set = MaskDataset(tokenizer, test_data, MAX_SEQ_LEN) train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True , collate_fn=collate_fn) valid_loader = DataLoader(valid_set, batch_size=BATCH_SIZE, collate_fn=collate_fn) test_loader = DataLoader(test_set, batch_size=BATCH_SIZE, collate_fn=collate_fn)
1 2 3 4 5 6 from transformers import BigBirdForMaskedLM""" model.resize_token_embeddings(len(tokenizer)) 要加上这句话,因为新加了 token """ model = BigBirdForMaskedLM.from_pretrained('google/bigbird-roberta-base' ) model.resize_token_embeddings(len (tokenizer)) model.to(device)
完整代码: