1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| ======================= Start pretraining ==============================
Epoch [1/6], global step [4442/26652], PT Loss: 0.6695, Val Loss: 0.6873
Epoch [2/6], global step [8884/26652], PT Loss: 0.6504, Val Loss: 0.6829
Epoch [3/6], global step [13326/26652], PT Loss: 0.6436, Val Loss: 0.6726
Epoch [4/6], global step [17768/26652], PT Loss: 0.6333, Val Loss: 0.6459
Epoch [5/6], global step [22210/26652], PT Loss: 0.6185, Val Loss: 0.6076
Epoch [6/6], global step [26652/26652], PT Loss: 0.6044, Val Loss: 0.6007
Pre-training done!
======================= Start training =================================
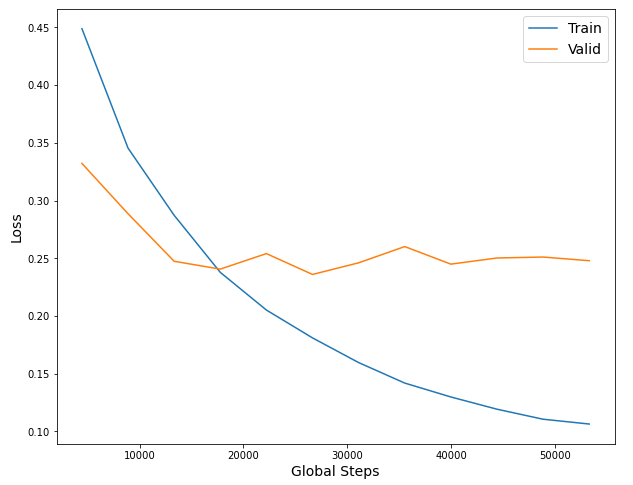
Epoch [1/12], global step [4442/53304], Train Loss: 0.4489, Valid Loss: 0.3322
Epoch [2/12], global step [8884/53304], Train Loss: 0.3454, Valid Loss: 0.2886
Epoch [3/12], global step [13326/53304], Train Loss: 0.2872, Valid Loss: 0.2474
Epoch [4/12], global step [17768/53304], Train Loss: 0.2378, Valid Loss: 0.2406
Epoch [5/12], global step [22210/53304], Train Loss: 0.2052, Valid Loss: 0.2541
Epoch [6/12], global step [26652/53304], Train Loss: 0.1811, Valid Loss: 0.2360
Epoch [7/12], global step [31094/53304], Train Loss: 0.1597, Valid Loss: 0.2461
Epoch [8/12], global step [35536/53304], Train Loss: 0.1419, Valid Loss: 0.2602
Epoch [9/12], global step [39978/53304], Train Loss: 0.1299, Valid Loss: 0.2449
Epoch [10/12], global step [44420/53304], Train Loss: 0.1193, Valid Loss: 0.2503
Epoch [11/12], global step [48862/53304], Train Loss: 0.1106, Valid Loss: 0.2511
Epoch [12/12], global step [53304/53304], Train Loss: 0.1064, Valid Loss: 0.2479
Training done!
|