0%
小样本分类训练模型 PET 和 P-tuning
MLM
MLM,全称 “Masked Language Model”,可以翻译为 “掩码语言模型”,实际上就是一个完形填空任务,随机 Mask 掉文本中的某些字词,然后要模型去预测被 Mask 的字词,示意图如下:
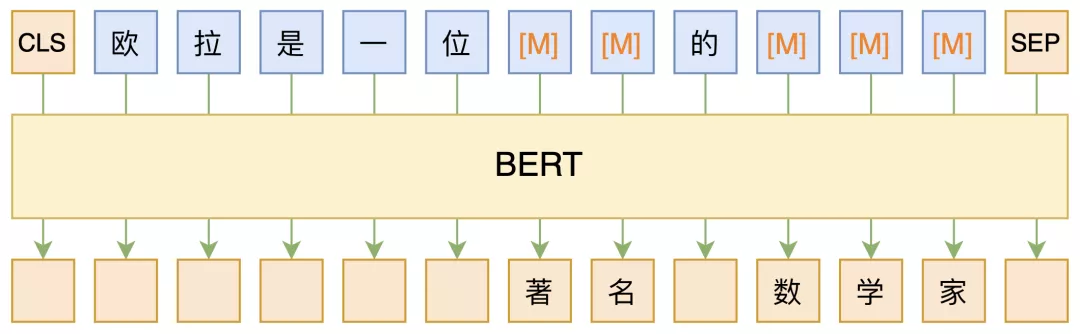
其中被 Mask 掉的部分,可以是直接随机选择的 Token,也可以是随机选择连续的能组成一整个词的 Token,后者称为 WWM(Whole Word Masking)。
开始,MLM 仅被视为 BERT 的一个预训练任务,训练完了就可以扔掉的那种,因此有一些开源的模型干脆没保留 MLM 部分的权重,然而,随着研究的深入,研究人员发现不止 BERT 的 Encoder 很有用,预训练用的 MLM 本身也很有用。
soft label 和 hard label
soft label:软标签,例如:probs 0.3, 0,8, 0,2…
hard label:硬标签,例如:实际label值 0, 1, 2…